
WEB APIはスクレイピングのようなものでWEB上へ条件を指定してリクエストを送ると、欲しいデータが返ってくるという、WEBサイト側が提供してくれるシステムです
スクレイピングは禁止されているサイトもありますが、APIはサイト側が用意してくれるデータなので安心してデータ収集を行うことができます
ここでは楽天市場APIを使いながら学んでいきたいと思います
・楽天ウェブサービスでアプリ作成
下記のサイトで楽天会員にサインインしてAPP作成します
楽天ウェブサービス https://webservice.rakuten.co.jp/
サインインしたら右上のNew APP からアプリケーションの作成をします
次のページで色々入力しますが、どれも重要なことではないので適当に入力します
英語だったりするのでグーグル翻訳すればわかると思います
テスト用ならアプリケーション名とかURLはなんでもいいと思います
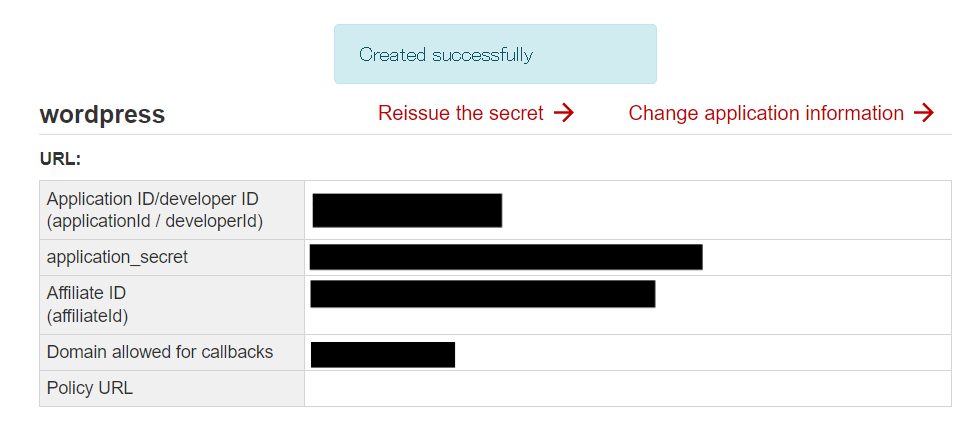
そうしたらアプリケーションの作成が完了したと思いますので Application ID/developer IDという数字をコピーしておきます
次に楽天ウェブサービスのトップページのメニューバーより API を選択します
楽天市場系APIより、楽天商品検索APIを選択します
リクエストURLを確認します
長いURLですが、? の前までがベースとなるリクエストURLになります
そして、リクエストURLにパラメータを渡します
まず Application ID は必須で、検索キーワードを指定します
ここまで理解出来たらコードを書いていきます
・WEB APIからjsonファイル取得
import requests
import pandas as pd
import os
from dotenv import load_dotenv
import json
# .envファイルの内容を読み込む
load_dotenv()
APP_ID = os.environ["APP_ID"]
#キーワード指定
keyword="DSライト アシックス"
#リクエストURL指定
url="https://app.rakuten.co.jp/services/api/IchibaItem/Search/20220601"
#パラメーター指定
params={
'applicationId':APP_ID,
'keyword':keyword,
'hits':1
}
#リクエスト
r=requests.get(url,params)
#jsonファイルに変換
r_json=r.json()
#jsonファイルとして相対パス指定して保存 'W'は書き込みのwrite
#日本語が文字化けしないように utf-8でエンコーディング
#ensure_ascii=FalseでASCII文字をエスケープさせない
with open('scr_f/data.json', 'w', encoding='utf-8') as file:
json.dump(r_json, file, ensure_ascii=False, indent=4)
#インデントを4で整形して表示
print(json.dumps(r_json, ensure_ascii=False, indent=4))APP ID は、.envファイルより読み込みました
今回はテストなので、1件だけ取得してパラメータは最小限に解りやすくしてます
dotenv を使ったパスワード管理については以下の記事を参考にしてください

リクエストで取得したデータをjsonファイルとして変換して表示しました
jsonファイルは日本語が文字化けするので、utf-8でエンコーディングして、ensure_ascii=False でASCII文字を含む場合はFalseに設定してエスケープされないようにします
jsonファイルは様々なアプリケーションやプログラミング言語で読み込めるファイル形式になります
しかし、このままではデータに不要な情報も多く、扱いずらいのでデータを整理していきます
{
"GenreInformation": [],
"Items": [
{
"Item": {
"affiliateRate": 4,
"affiliateUrl": "",
"asurakuArea": "",
"asurakuClosingTime": "",
"asurakuFlag": 0,
"availability": 1,
"catchcopy": "",
"creditCardFlag": 1,
"endTime": "",
"genreId": "302277",
"giftFlag": 0,
"imageFlag": 1,
"itemCaption": "◇部活生に向けた、フィット性に優れたカンガルーレザー採用モデル。かかと部にGEL technologyを採用。最後まで走りきりたいという部活生の想いに応えるため、足への負担を軽減する fuzeGEL をかかと部に搭載。またソール材をソライトポリマーから耐摩耗ウレタンにアップデートすることで、耐久性が約2倍に向上。さらにかかと部は高硬度と中硬度の2層構造で突き上げを軽減■カラー(メーカー表記):ブラック×イエロー(002:BLACK/SAFETY YELLOW)■甲材(アッパー):カンガルー■底材(ソール):【アウターソール】合成底【インナーソール】合成樹脂(取替式)■用途(コートサーフェス):土・人工芝兼用■ワイズ:3E■片足重量:約250g■片足重量代表サイズ:26.5cm■生産国:ベトナム■2023年モデル※ワイズを確認の上お買い求め下さい。また、足のサイズは甲高、幅等個人差がありますので、あくまで目安としてご判断ください。アルペン alpen スポーツデポ SPORTSDEPO サッカー スパイク シューズ サッカースパイク サッカーシューズ 靴 一般 大人 230714_82asec 82_23FWCL",
"itemCode": "alpen:10431509",
"itemName": "最大10%OFFクーポン 【10/24〜10/27】 アシックス DS LIGHT WIDE ディーエス ライト ワイド 1103A069 DSライト メンズ サッカー スパイクシューズ 3E : ブラック×イエロー asics",
"itemPrice": 7990,
"itemPriceBaseField": "item_price_min3",
"itemPriceMax1": 7990,
"itemPriceMax2": 7990,
"itemPriceMax3": 7990,
"itemPriceMin1": 7990,
"itemPriceMin2": 7990,
"itemPriceMin3": 7990,
"itemUrl": "https://item.rakuten.co.jp/alpen/8200124953/?rafcid=wsc_i_is_1091865320853160354",
"mediumImageUrls": [
{
"imageUrl": "https://thumbnail.image.rakuten.co.jp/@0_mall/alpen/cabinet/241023/1_18/8200124953_1.jpg?_ex=128x128"
}
],
"pointRate": 1,
"pointRateEndTime": "",
"pointRateStartTime": "",
"postageFlag": 1,
"reviewAverage": 5,
"reviewCount": 2,
"shipOverseasArea": "",
"shipOverseasFlag": 0,
"shopAffiliateUrl": "",
"shopCode": "alpen",
"shopName": "アルペン楽天市場店",
"shopOfTheYearFlag": 0,
"shopUrl": "https://www.rakuten.co.jp/alpen/?rafcid=wsc_i_is_1091865320853160354",
"smallImageUrls": [
{
"imageUrl": "https://thumbnail.image.rakuten.co.jp/@0_mall/alpen/cabinet/241023/1_18/8200124953_1.jpg?_ex=64x64"
}
],
"startTime": "",
"tagIds": [
1000860,
1039858,
1000874,
1000886,
1000367,
1000380,
1000379,
1001563,
1000378,
1000377,
1000374,
1000373,
1000372,
1000371,
1000370,
1000369,
1000368
],
"taxFlag": 0
}
}
],
"TagInformation": [],
"carrier": 0,
"count": 852,
"first": 1,
"hits": 1,
"last": 1,
"page": 1,
"pageCount": 100
}・商品情報取得、データ整形、出力
まず、商品のタイトルとなる “itemName” を取り出します
#最上段の "GenreInformation": [] を除く
items=r_json["Items"]
#Itemsというリストの中の最初の要素を指定して、変数itemに格納
item=items[0]
#商品情報は辞書型キー"Item"の中に入っているので、変数item_infoに格納
item_info=items[0]["Item"]
#商品名は"itemName"に入っているので、変数item_nameに格納
item_name=items[0]["Item"]["itemName"]
print(item_name)
#最大10%OFFクーポン 【10/24〜10/27】 アシックス DS LIGHT WIDE ディーエス ライト ワイド 1103A069 DSライト メンズ サッカー スパイクシューズ 3E : ブラック×イエロー asics“Items”というリストから一つ取り出し、その中の”Item”の中の商品情報から商品名を抽出しました
pythonの辞書の扱い方に慣れれば簡単だと思います
実務では大量のデータを取得すると思うので、これらをfor文で繰り返し、一つずつ抽出していきます
#最上段の "GenreInformation": [] を除く
r_json_list=r_json["Items"]
#商品情報リスト定義
detail_list=[]
#for文で商品詳細取得
for i in range(len(r_json_list)):
item_info=r_json_list[i]
#商品詳細取得
item_name=item_info["Item"]["itemName"]
item_price=item_info["Item"]["itemPrice"]
shop_name=item_info["Item"]["shopName"]
item_url=item_info["Item"]["itemUrl"]
#辞書型に格納
detail_dict={'商品名':item_name,'価格':item_price,'店名':shop_name,'URL':item_url}
#リストに追加
detail_list.append(detail_dict)
#データフレームに変換、エクセル出力
df=pd.DataFrame(detail_list)
df.to_excel(f"rakuten_deta_{keyword}.xlsx")これでデータ件数が増えてもfor文で回して詳細を取得できます
最後、エクセル出力して保存します
ファイル名は f文字列 を使用しています
使い方は以下の記事を参照してください



コメント