
以前の記事で、youtubeの動画から音声ファイルをダウンロードして保存する方法を紹介しまし
今回は、その音声ファイルを使って文字起こしをするプログラミングをやってみたいと思います
・環境
windows 11
google colab
openai-whisper-20240930
・whisperを使った音声ファイルから文字起こし
音声ファイルをテキストとして変換するために OpenAI のwhisperという音声認識モデルを使用します
日本語はもちろん、メジャーな言語は大体対応していて、素晴らしい精度で認識してくれます
ただ、ローカル環境で使うにはPCのスペックがかなり高くないと使えません
GPUのないノートパソコンや、性能の低いGPUしかない場合は時間がすごいかかったりします
そこで、自分は無料でGPUを使用できるgoogle colabを使っていきたいと思います
google colabはgoogleアカウントさえ持っていればすぐに始めることができるので早速使っていきましょう
google colabのノートブック(新規ファイル)を開いたらまずはGPUの設定をします

ランタイムから、T4(GPU)を選択して保存します
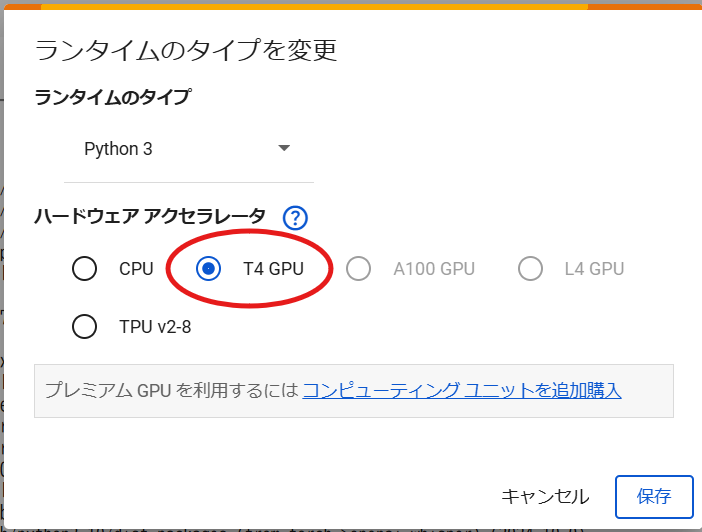
これでGPUを使うことができます
次に、google colabでコードを書いていきます
一番上のセルから、以下のコードを実行していきます
!pip install openai-whispergoogle colabでpipコマンドを実行する場合は、最初に ! マークを付けます
これでライブラリをインストールできました
次に、ライブラリをimportします
import whisper次にwhhisperのモデルを生成します
モデルには種類があって上位のモデルほど時間はかかりますが、文字認識の制度が上がります
ここでは標準くらいのbaseモデルを選択します
tiny < base < small < medium < largeで、大きくなるほど性能が高いです
model=whisper.load_model("base")次に音声ファイルをgoogle colabで読み込むために、google driveと接続します
google colabはローカルではないので、使用するファイルなどはgoogle driveへアップロードする必要があります
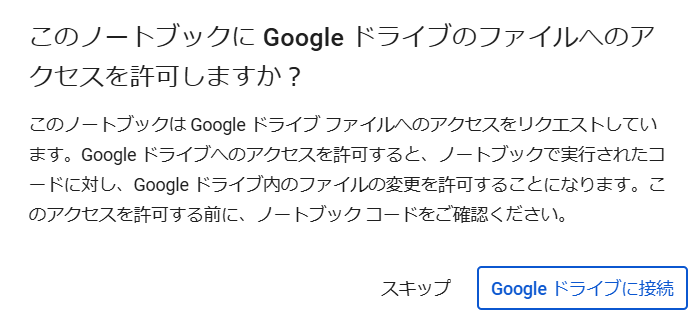
以下のコマンドで、google driveと接続します
from google.colab import drive
drive.mount('/content/drive')接続確認のポップアップが表示されるので接続を選択して、googleアカウントを選択します
次に、読み込むファイルのパスを指定します
path_audio = "/content/drive/MyDrive/audio/sample_audio.mp3"自分は、Mydriveの中にaudioのフォルダを作り、その中にmp3ファイルを入れました
次に、whisper modelで文字起こしをします
result=model.transcribe(path_audio)少し時間がかかると思いますが、これで音声ファイルから文字起こしができました
ちなみにテキストを翻訳することもできます
その場合は、以下のコマンドのように、language=”en”と言語を指定します
英語の音声を日本語のテキストにしたいなら”ja”を指定します
result = model.transcribe(path_audio, language="en")結果を見てみます
print(result["text"])結果は辞書型データなので、resultの中のキーのtextを表示します
テキストが取得できたと思います
次にテキストファイルとして保存してみます
text=result["text"]先ほどの結果のテキストをtextという変数に代入します
with open("/content/drive/MyDrive/text/sample_text.txt", "w") as f:
f.write(text)次にwモードでファイルを開き、書き込むファイル名、パスを指定します
そしてtextを書き込みます
これで、音声ファイルからテキストを抽出して、テキストファイルを生成することができました


コメント