
大量の書類や写真から、文字を抜き取って他のファイルに書き込むような作業にうってつけの機能が光学文字認識(OCR)です
以前の記事で、画像加工ライブラリのpillowを紹介しました

さらに光学文字認識のライブラリを使用して、画像から文字を読み取るコードを作っていきたいと思います
・環境
windows 11
pyocr 0.8.5
pillow 11.0.0
・tesseractのインストール
tesseractは、光学文字認識エンジンのフリーソフトです
日本語の他にも、主要な言語はほとんど対応しています
以下のサイトでtesseractのインストーラーをダウンロードします
windows(64bit)の方は、以下の写真の場所
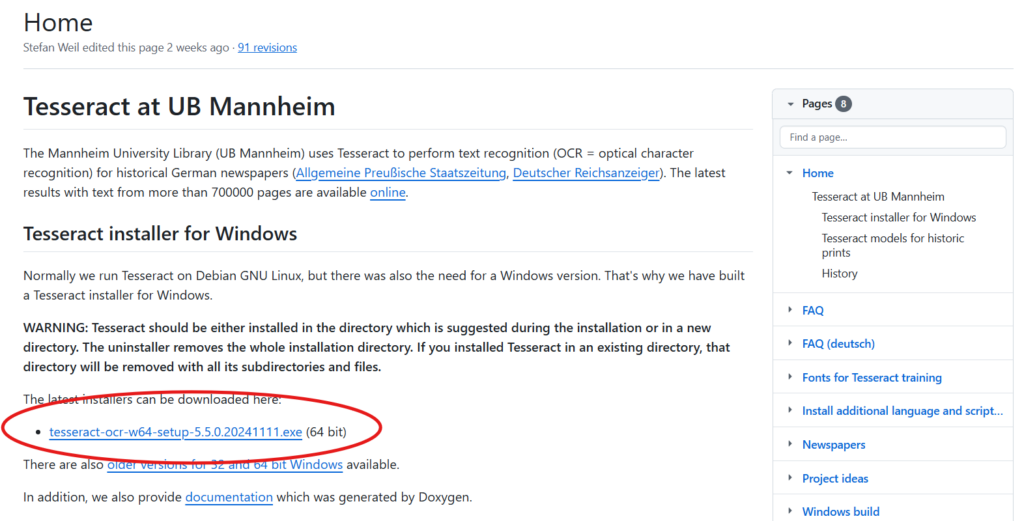
その後、ダイアログボックスの通りにインストールします
tesseractのパスの環境変数設定
[Windows]+[Pause]キーを押して、[設定]アプリの[システム]-[バージョン情報]画面(Windows 10の場合は[Windowsの設定]アプリの[システム]-[詳細情報]画面)を開きます
システムの詳細設定を開いて、環境変数を選択
ユーザーの環境変数のPathを編集して、新規でtesseractのpathを入力します
おそらくwindowsの方は “C:\Program Files\Tesseract-OCR”に入っていると思います
日本語学習データのダウンロード
以下のサイトで、日本語の学習データをダウンロードします
ダウンロードするボタンが右のほうにあります

ダウンロードしたら、”C:\Program Files\Tesseract-OCR\tessdata”のディレクトリに保存します
・コード作成
まず必要なライブラリをインストールします
pip install pyocr
pip install pillow画像から文字を取得する、一番シンプルなコードを書いてみます
from PIL import Image
import pyocr
import pyocr.builders
#tesseractのパス指定、環境変数に設定しているならこの行は不要
pyocr.tesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
#OCRエンジン(文字認識ツール)の作成
tools = pyocr.get_available_tools()
tool = tools[0]
#文字認識したい画像ファイルのパスを格納
img_path = r"C:\Users\Documents\sample_img.jpg"
img = Image.open(img_path)
#builder設定
builder = pyocr.builders.TextBuilder(tesseract_layout=3)
#OCR実行、文字を取得
text = tool.image_to_string(img, lang="eng+jpn", builder=builder)
#文字をテキストファイルに保存
with open(r"C:\Users\Documents\sample_text.txt", "w") as text_file:
text_file.write(text)コードを解説していきます
#OCRエンジン(文字認識ツール)の作成
tools = pyocr.get_available_tools()
tool = tools[0]pyocrで使用できるOCRエンジンのtoolの一覧を取得します
おそらく今はtesseractしか入っていないので、toolsの0番目にあるtesseractをtoolとしてを使用します
#builder設定
builder = pyocr.builders.TextBuilder(tesseract_layout=3)builderの設定を行います
今回はTextBuilderを使用していますが、builderにはいくつか種類があります
| TextBuilder | 文字や数字を認識 |
| WordBoxBuilder | 単語の位置や内容を認識 |
| LineBoxBuilder | 行の位置や内容を認識 |
| DigitBuilder | 数字や記号を認識 |
| DigitLineBoxBuilder | 数字や記号の位置を認識 |
builderの引数にtesseract_layout=3を設定しました
これは文字の認識レイアウトに関する設定です
詳細についてはコマンドプロンプトやターミナルで、tesseract –help-extraと入力すると確認できます
3や6がよく使われているような気がします
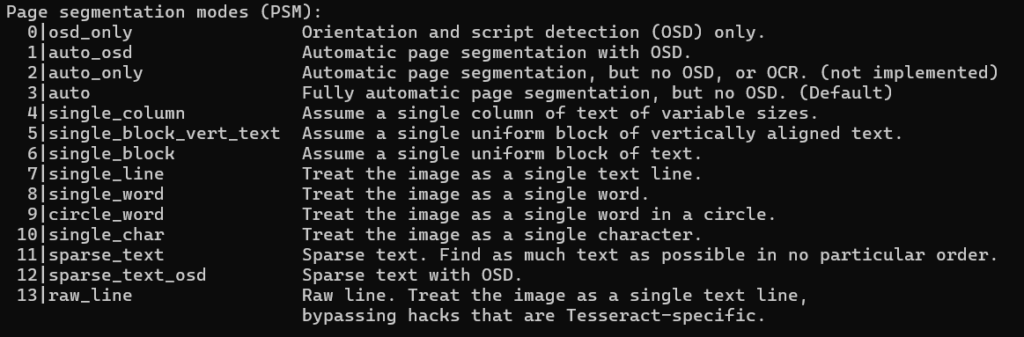
DeepL.comで翻訳してみました。
0|osd_only オリエンテーションとスクリプト検出 (OSD) のみ。
1|auto_osd 自動ページ分割と OSD。
2|auto_only 自動ページ分割、ただし OSD ・ OCR はなし。(実装されていない)
3|auto 完全自動ページ分割。(デフォルト)
4|single_column テキス ト 1 列を想定。
5|single_block_vert_text 縦組みテキス ト の単一統一ブ ロ ッ ク を想定。
6|single_block 一様な単一のテキスト・ブロックを想定する。
7|single_line 画像を 1 行のテキストとして扱う。
8|single_word 画像を一つの単語として扱う。
9|circle_word 画像を円内の単一の単語として扱う。
10|single_char 画像を一文字として扱う。
11|sparse_text 疎なテキスト。できるだけ多くのテキストを順不同に検索する。
12|sparse_text_osd OSD 付きの疎なテキスト。
13|raw_line 生行。画像を1行のテキストとして扱う、
Tesseract固有のハックをバイパスする。
これは数をこなして慣れていくしかないかなと思いました
#OCR実行、文字を取得
text = tool.image_to_string(img, lang="eng+jpn", builder=builder)先ほど設定したtoolを使って画像から文字を取得するOCRを実行します
引数には、ファイルパス、読み取る言語、builderを指定します
結果を変数textに格納します
#文字をテキストファイルに保存
with open(r"C:\Users\Documents\sample_text.txt", "w") as text_file:
text_file.write(text)最後にテキストファイルとして保存してみました


コメント